데이터 베이스의 기본
데이터 베이스(DataBase - DB)
- 일정한 규칙을 통해 구조화되어 저장되는 데이터의 모음
- DB를 제어, 관리하는 통합 시스템을 DBMS(DataBase Management System)라고 함
- 실시간 접근 및 동시 공유 가능
- 아래는 프로그램과 DBMS, DB간의 관계도를 그림으로 나타낸 것.

엔터티(entity)
- 여러 개의 속성을 가진 명사
- A가 혼자서 존재하지 못하고, B의 존재에 따라 종속적이라면, A는 약한 엔티티, B는 강한 엔티티 (ex. 방 : 약한, 건물 : 강한)
릴레이션(relation)
- DB 에서 정보를 구분하여 저장하는 기본 단위
- 관계형 데이터베이스 → " 테이블 ", NoSQL 데이터베이스 → " 컬렉션 "로 칭함
- 행 하나(레코드)의 집합 → 릴레이션의 집합 → 테이블의 집합 → 데이터베이스
- 엔티티와 릴레이션은 아래의 그림 참고

속성(attribute)
- 릴레이션에서 관리하는 고유한 이름을 갖는 정보
도메인(domain)
- 각각의 속성이 가질 수 있는 값들의 집합(ex. 성별의 값 {남,여} )
필드와 레코드
- 필드 : 각 열의 이름 (ex. 주소, 아이딩, 이름, 폰번호 등)
- 레코드 : 각 행. 튜플이라고도 함.
- 필드 타입 (1) - 숫자
| 타입 | 용량(Byte) | min(부호 O) | max(부호 X) |
| tinyint | 1 | -128 | 127 |
| int | 4 | -21억...8 | 21억...7 |
- 필드 타입 (2) - 문자
| 타입 | 특징 및 설명 |
| Char | - 고정 길이 문자열 (0~255) - ex. char(100) → 10byte 써도 100byte로 저장(메모리낭비) |
| Varchar | - 가변 길이 문자열 (0~65535) - 글자 길이 + 1바이트 (길이 기록용) - ex. varchar(100) → 10byte 쓰면 , 10 + 1 = 11byte 사용 |
| Text | - 게시판의 본문 저장 용도 ( 큰 문자열 저장) |
관계

- 1 : 1 관계 예시 : 한 유저당 주민등록번호는 하나다.
- 1: N 관계 예시 : 한 유저당 여러개의 상품을 선택할 수 있다.
- N : M 관계 예시 : 여러명의 학생은 여러강의를 들을 수 있다.
키

- 유일성 : 중복되는 값이 없음
- 최소성 : 필드를 조합하지 않고 최소 필드만 써서 키를 형성할 수 있는 것
- 기본키(Primary Key)
- 유일성과 최소성을 만족하는 키
- 외래키(Foreign Key)
- 다른 테이블의 PK를 그대로 참조하는 값
- 개체와의 관계 식별에 사용
- 후보키(Candidate Key)
- 기본키가 될 수 있는 후보들
- 유일성 과 최소성을 동시 만족하는 키
- 대체키(alternate Key)
- 후보키가 두개 이상일 경우, 하나를 기본키로 지정하고 남은 후보키
- 슈퍼키(super Key)
- 각 레코드(행) 을 유일하게 식별할 수 있는 유일성을 갖춘 키
ERD와 정규화
ERD? (Entity Relationship Diagram)
- 릴레이션 간의 관계를 정의한 것
ERD의 예시
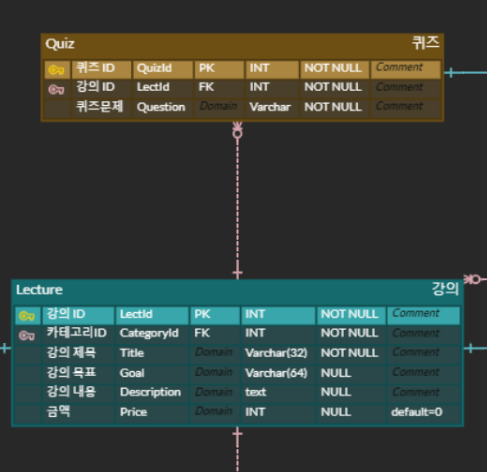
정규화 과정
- 릴레이션 간의 종속 관계로 인해 DB 이상현상을 해결하거나, 저장 공간의 효율화를 위해 릴레이션을 여러개로 분리하는 과정
- 1 정규형
- 릴레이션의 모든 도메인이 원자 값 (하나의 값)으로 구성되게 하는 정규화 방법

- 2 정규형
- 릴레이션이 1 정규형이며, 부분 함수의 종속성을 제거한 형태
- 즉, 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속적인 것.
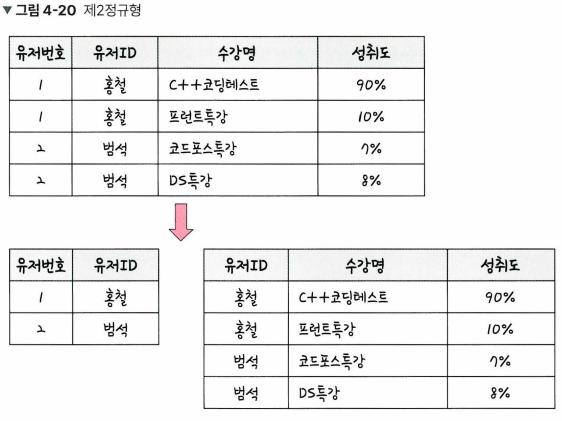
- 3 정규형
- 제 2정규형이고, 기본키가 아닌 모든 속성이 이행적 함수 종속을 만족하지 않는 상태
- 이행적 함수 종속 : A → B , B → C then, A → C

- BCNF 정규형 (보이스/코드 정규형)
- 제 3 정규형이며, 결정자가 후보키가 아닌 함수 종속 관계를 제거하여 모든 결정자가 후보키인 상태
- 결정자 : X → Y 일때, X는 결정자, Y는 종속자
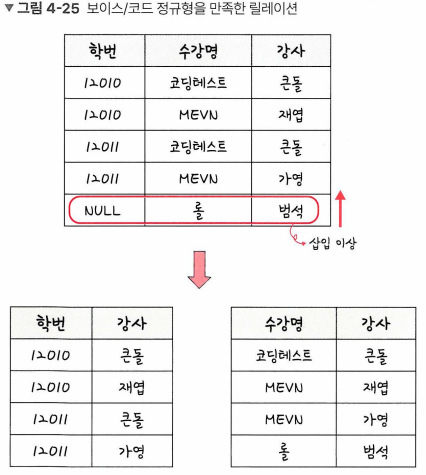
데이터 베이스의 종류
관계형 데이터베이스
- 행과 열을 가지는 표 형식 데이터
- SQL을 활용하여 조작
- MySQL, PostgreSQL, Oracle 등이 있음
NoSQL 데이터베이스
- Not only SQL로, SQL을 사용하지 않는 데이터베이스
- MongoDB, redis 등이 있음.
MySQL
| 특징 | 장점 | 단점 | 활용법 |
| - 오픈소스 관계형 DB - 구조화된 SQL 사용 - ACID(Atomicity, Consistency, Isolation, Durability) 보장 |
- 성능이 우수하고 가벼운 DBMS - 오픈소스로 무료 사용 가능 - 다양한 플랫폼과 호환 가능 - 데이터 복제 및 백업 기능 지원 |
- 복잡한 쿼리 수행 시 성능이 다소 떨어질 수 있음 - 고도화된 데이터 분석 및 대규모 트랜잭션 처리에 한계 |
- 웹 애플리케이션 (WordPress, 전자상거래, CMS) - 중소규모의 DB 시스템 - 정형, 구조적 데이터 |
PostgreSQL
| 특징 | 장점 | 단점 | 활용법 |
| - 확장성과 ACID 트랜잭션 지원 - JSON, XML 등의 비정형 데이터도 저장 가능 - 다양한 인덱싱 기법 및 고급 기능 제공 |
- 복잡한 쿼리 처리에 강력한 성능 제공 - 데이터 무결성 보장 및 트랜잭션 관리 우수 - 다양한 확장 기능과 플러그인 지원 |
- 상대적으로 MySQL보다 무겁고 학습 난이도가 높음 - 설정과 튜닝이 어렵고 초기 설정이 복잡할 수 있음 |
- 대규모 데이터 처리 시스템 - GIS(지리 정보 시스템) 및 JSON 데이터 처리 |
MongoDB
| 특징 | 장점 | 단점 | 활용법 |
| - 문서 기반 NoSQL DB - JSON과 유사한 BSON(Binary JSON) 형식으로 데이터 저장 - 동적 데이터 구조 변경 가능 |
- 스키마리스 구조로 유연한 데이터 모델링 가능 - 높은 확장성과 분산 저장 기능 제공 - 복잡한 JOIN 연산 없이도 빠른 데이터 조회 가능 |
- 트랜잭션을 보장하지 않음 - 데이터 중복이 발생할 가능성이 있음 |
- 실시간 데이터 분석 및 로깅 시스템 - 대량의 JSON 데이터 처리 (IoT, 소셜 미디어) |
Redis
| 특징 | 장점 | 단점 | 활용법 |
| - 키-값 저장 방식의 인메모리 DB - 데이터가 메모리에 저장되어 빠른 속도 제공 - 다양한 데이터 구조(List, Set, Hash, Sorted Set) 지원 |
- 초고속 데이터 처리 속도 (메모리 기반) - 단순한 구조로 빠른 데이터 조회 가능 -[ 캐싱, 세션 저장, 실시간 분석에 최적화 |
- 데이터가 메모리에 저장되므로 데이터 크기 제한이 있음 - 복잡한 데이터 관계 처리가 어려움 |
- 세션 관리, 캐싱 (웹 서버의 로그인 세션 유지) - 실시간 순위 및 카운팅 (SNS 좋아요, 댓글 수) - 메시지 큐 시스템 (Pub/Sub 모델 지원) |
'CS > 데이터베이스' 카테고리의 다른 글
| (CS) 데이터베이스 - 질문 (0) | 2025.03.12 |
|---|---|
| (CS) 데이터베이스 - 트랜잭션, 인덱스, 조인 (0) | 2025.03.11 |